【力扣438】找到字符串中所有字母异位词
题目
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
示例 1:
1 | 输入: s = "cbaebabacd", p = "abc" |
示例 2:
1 | 输入: s = "abab", p = "ab" |
提示:
1 <= s.length, p.length <= 3 * 104s和p仅包含小写字母
实现代码
和
【力扣76】最小覆盖字串思路一样,使用双指针的滑动窗口来实现
1 | class Solution { |
时间复杂度
最差的情况是left扫了一遍s2,right扫了一遍s2,那就是2*s,加上s1、s2所有字符集,最大26,去除常数最终的时间复杂度是O(N)
空间复杂度
额外空间left、right和两个数组,left和right的空间复杂度是O(1)可以不计,因为数组是存放字符次数的,大小取决于s1和s2不同字符的个数,最大也就26,所以去除常数的空间复杂度为O(1)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 青柠!
相关推荐

2025-09-13
【力扣167】两数之和II-输入有序数组
题目给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 <= index1 < index2 <= numbers.length 。 以长度为 2 的整数数组 [index1, index2] 的形式返回这两个整数的下标 index1 和 index2。 你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。 你所设计的解决方案必须只使用常量级的额外空间。 示例 1: 123输入:numbers = [2,7,11,15], target = 9输出:[1,2]解释:2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。返回 [1, 2] 。 示例 2: 123输入:numbers = [2,3,4], target = 6输出:[1,3]解释:2 与 4 之和等于目标数 6 。因此 index1 = 1, in...

2025-09-17
【力扣3】无重复字符的最长子串
题目给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 示例 1: 123输入: s = "abcabcbb"输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 示例 2: 123输入: s = "bbbbb"输出: 1解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。 示例 3: 1234输入: s = "pwwkew"输出: 3解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。 提示: 0 <= s.length <= 5 * 104 s 由英文字母、数字、符号和空格组成 实现代码 和【力扣76】最小覆盖字串思路一样,使用双指针的滑动窗口来实现 12345678910111213141516171819class Solution { pub...
2025-09-16
【力扣567】字符串的排列
题目给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的 排列。如果是,返回 true ;否则,返回 false 。 换句话说,s1 的排列之一是 s2 的 子串 。 示例 1: 123输入:s1 = "ab" s2 = "eidbaooo"输出:true解释:s2 包含 s1 的排列之一 ("ba"). 示例 2: 12输入:s1= "ab" s2 = "eidboaoo"输出:false 提示: 1 <= s1.length, s2.length <= 104 s1 和 s2 仅包含小写字母 实现代码 和【力扣76】最小覆盖字串思路一样,使用双指针的滑动窗口来实现 12345678910111213141516171819202122232425262728293031323334353637383940414243class Solution { public boolean checkInclusion(String...
2025-09-16
【力扣76】最小覆盖子串
题目给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。 注意: 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。 如果 s 中存在这样的子串,我们保证它是唯一的答案。 示例 1: 123输入:s = "ADOBECODEBANC", t = "ABC"输出:"BANC"解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 123输入:s = "a", t = "a"输出:"a"解释:整个字符串 s 是最小覆盖子串。 示例 3: 1234输入: s = "a", t = "aa"输出: ""解释: t 中两个字符 ...
2025-09-13
【力扣142】环形链表
题目给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。 不允许修改 链表。 示例 1: 123输入:head = [3,2,0,-4], pos = 1输出:返回索引为 1 的链表节点解释:链表中有一个环,其尾部连接到第二个节点。 示例 2: 123输入:head = [1,2], pos = 0输出:返回索引为 0 的链表节点解释:链表中有一个环,其尾部连接到第一个节点。 示例 3: 123输入:head = [1], pos = -1输出:返回 null解释:链表中没有环。 提示: 链表中节点的数目范围在范围 [0, 104] 内 -105 <= Node.val <= 105 pos 的值为 -1 或者...
2025-09-13
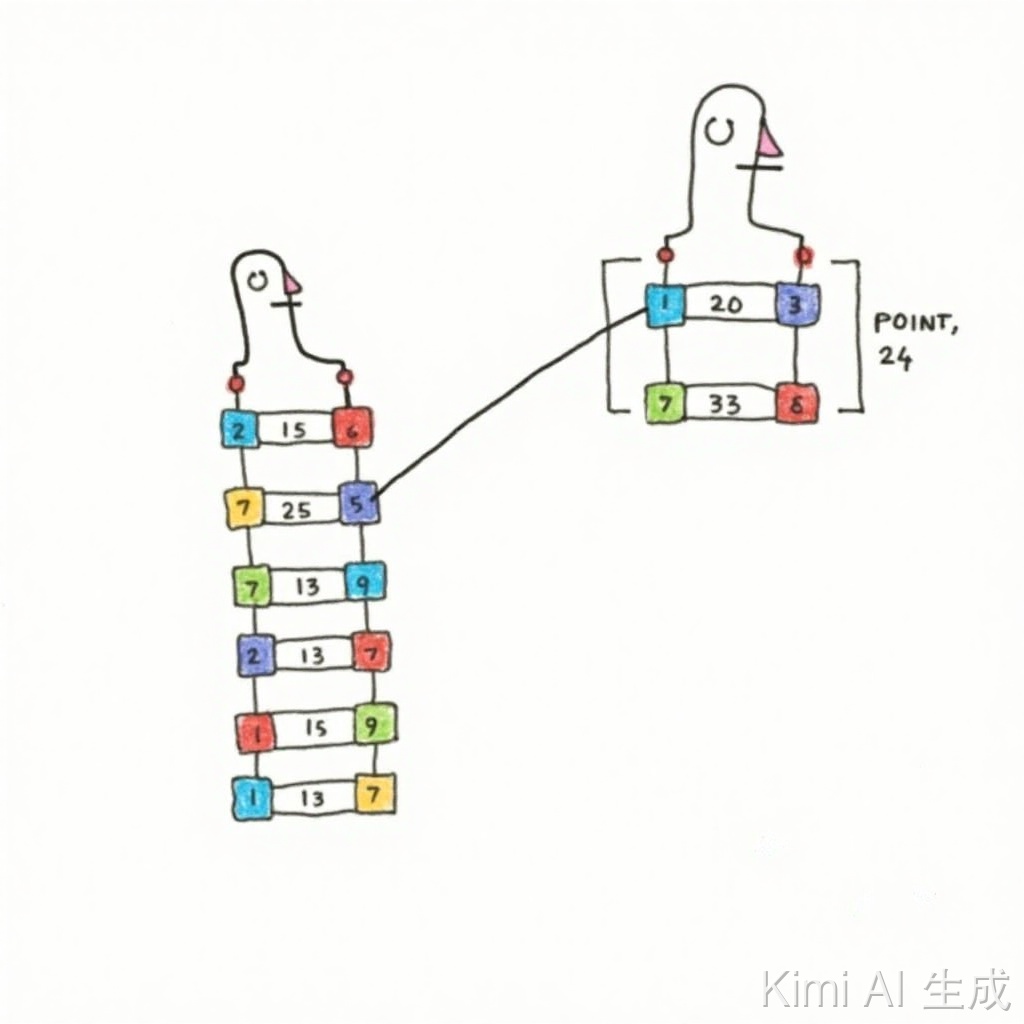
【力扣160】相交链表
题目给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 123456输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skip...
评论
系列文章